Simple web scraping with Node.js / JavaScript
Following up on my popular tutorial on how to create an easy web crawler in Node.js I decided to extend the idea a bit further by scraping a few popular websites. For now, I'll just append the results of web scraping to a .txt file, but in a future post I'll show you how to insert them into a database.
Each scraper takes about 20 lines of code and they're pretty easy to modify if you want to scrape other elements of the site or web page.
Web Scraping Reddit
First I'll show you what it does and then explain it.
It firsts visits reddit.com and then collects all the post titles, the score, and the username of the user that submitted each post. It writes all of this to a .txt file named reddit.txt separating each entry on a new line. Alternatively it's easy to separate each entry with a comma or some other delimiter if you wanted to open the results in Excel or a spreadsheet.
Okay, so how did I do it?
Make sure you have Node.js and npm installed. If you're not familiar with them take a look at the paragraph here.
Open up your command line. You'll need to install just two Node.js dependencies. You can do that by either running
npm install --save cheerio
npm install --save request
as shown below:
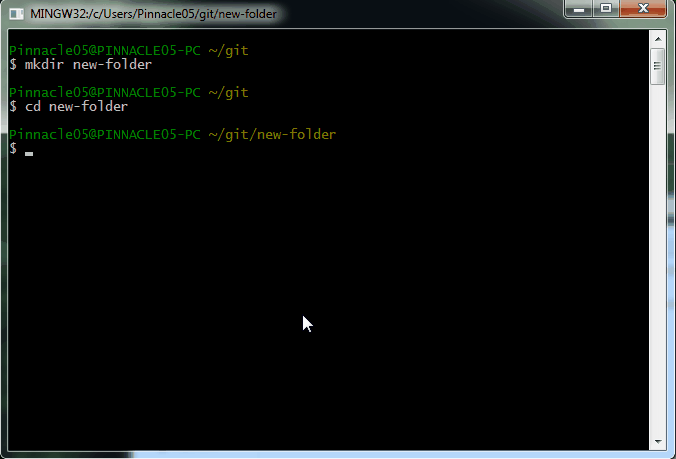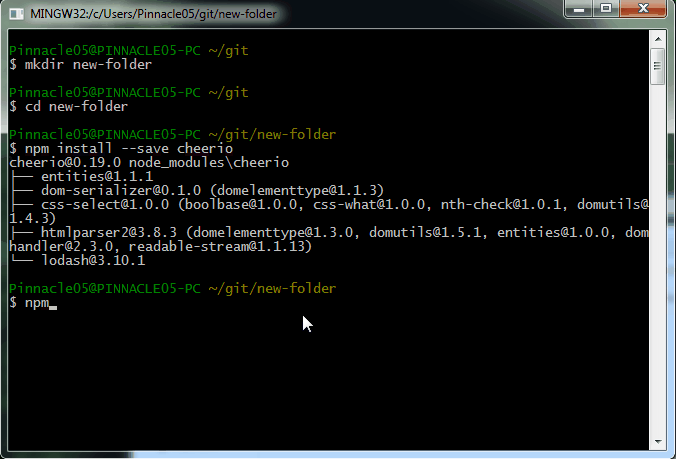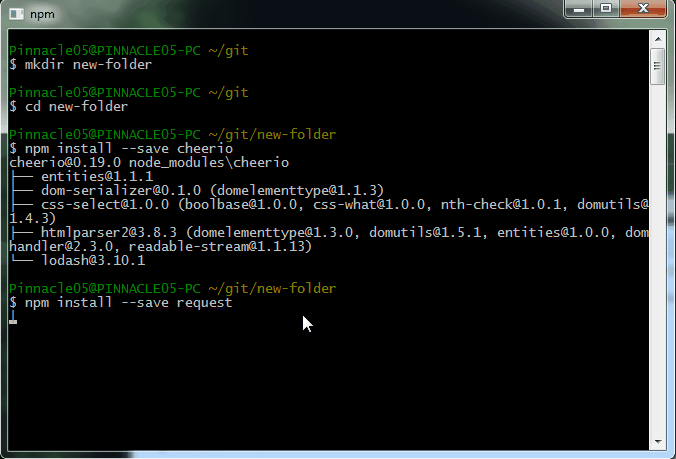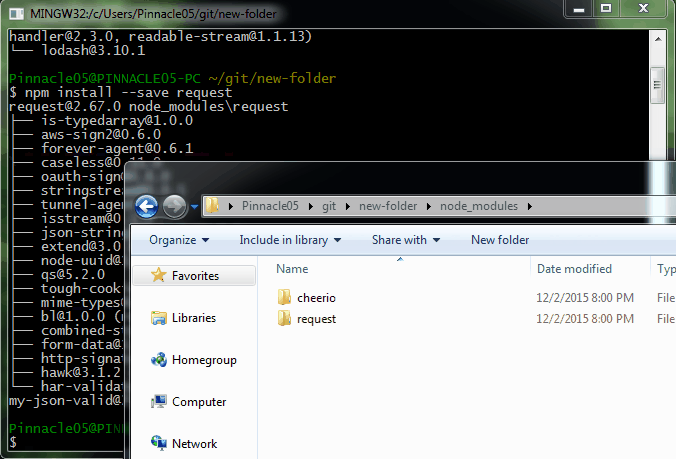
Alternate option to install dependencies
Another option is copying over the dependencies and adding them to a package.json file and then running npm install. My package.json includes these:
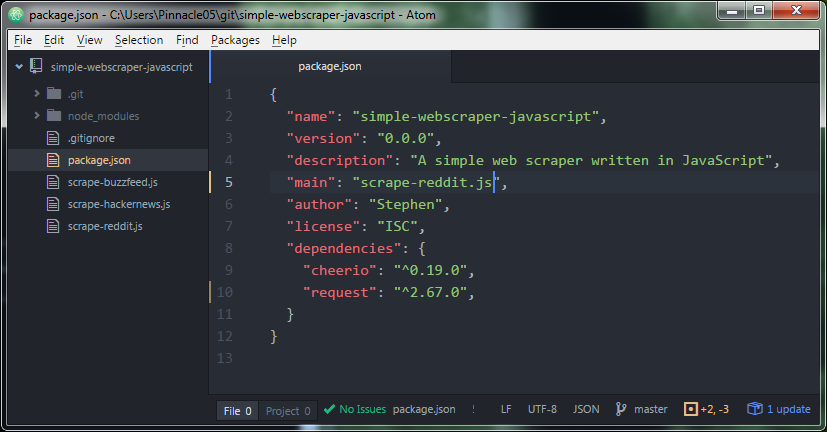
The actual code to scrape reddit
Now to take a look at how I scraped reddit in about 20 lines of code. Open up your favorite text editor (I use Atom) and copy the following:
var request = require('request');
var cheerio = require('cheerio');
var fs = require('fs');
request("https://www.reddit.com", function(error, response, body) {
if(error) {
console.log("Error: " + error);
}
console.log("Status code: " + response.statusCode);
var $ = cheerio.load(body);
$('div#siteTable > div.link').each(function( index ) {
var title = $(this).find('p.title > a.title').text().trim();
var score = $(this).find('div.score.unvoted').text().trim();
var user = $(this).find('a.author').text().trim();
console.log("Title: " + title);
console.log("Score: " + score);
console.log("User: " + user);
fs.appendFileSync('reddit.txt', title + '\n' + score + '\n' + user + '\n');
});
});
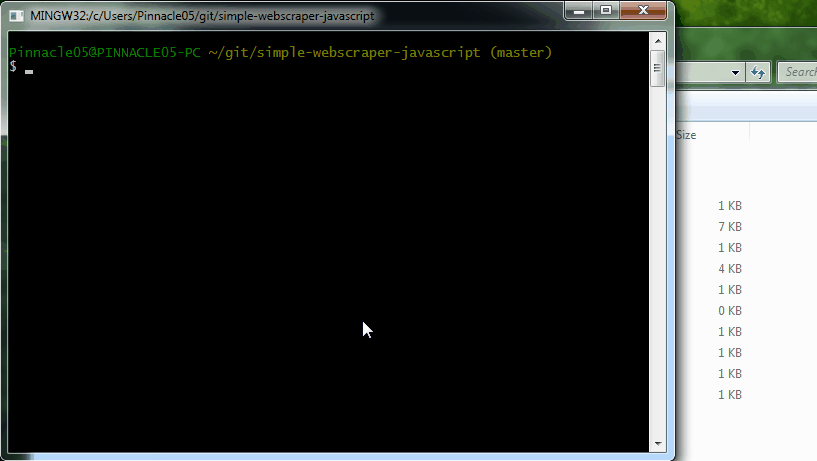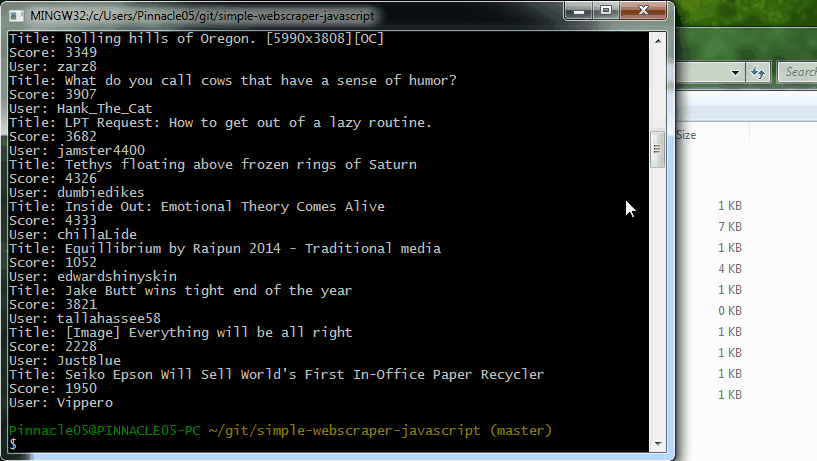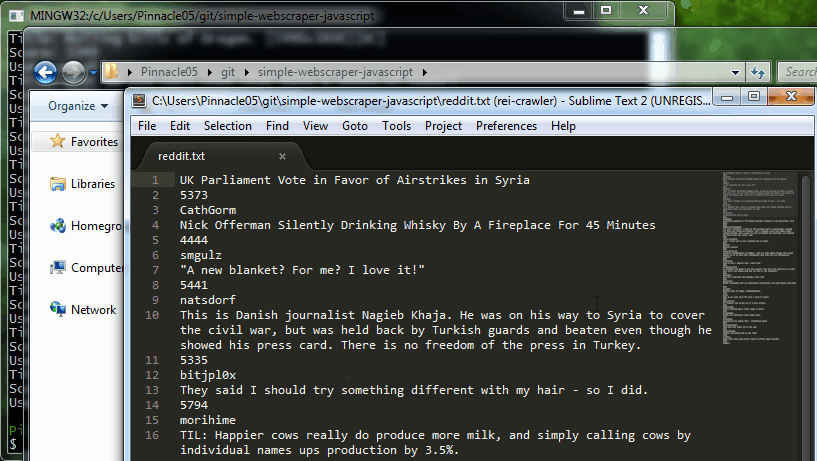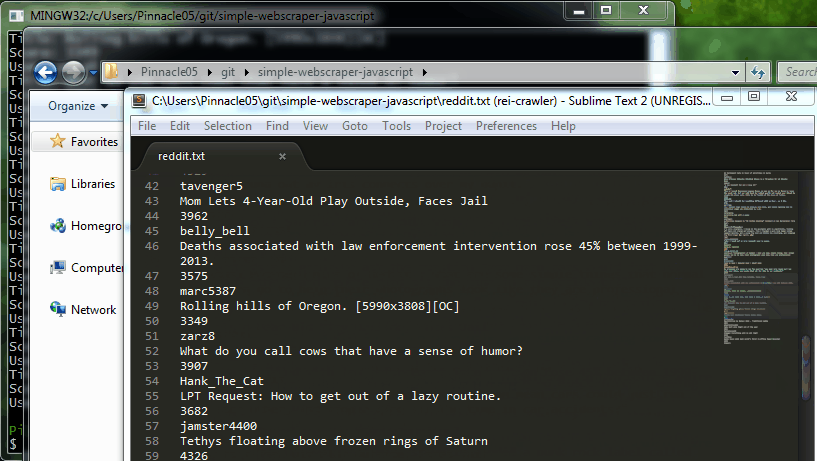
This is surprisingly simple. Save the file as scrape-reddit.js and then run it by typing node scrape-reddit.js. You should end up with a text file called reddit.txt that looks something like:
UK Parliament Vote in Favor of Airstrikes in Syria
5515
CathGorm
Harrison Ford, everybody
4569
DudeWiggles
Nick Offerman Silently Drinking Whisky By A Fireplace For 45 Minutes
5112
smgulz
"A new blanket? For me? I love it!"
5605
natsdorf
Playing basketball (Fallout 4)
2535
theone1221
... continued
which is the post title, then the score, and finally the username.
Web Scraping Hacker News
Let's take a look at how the posts are structured:
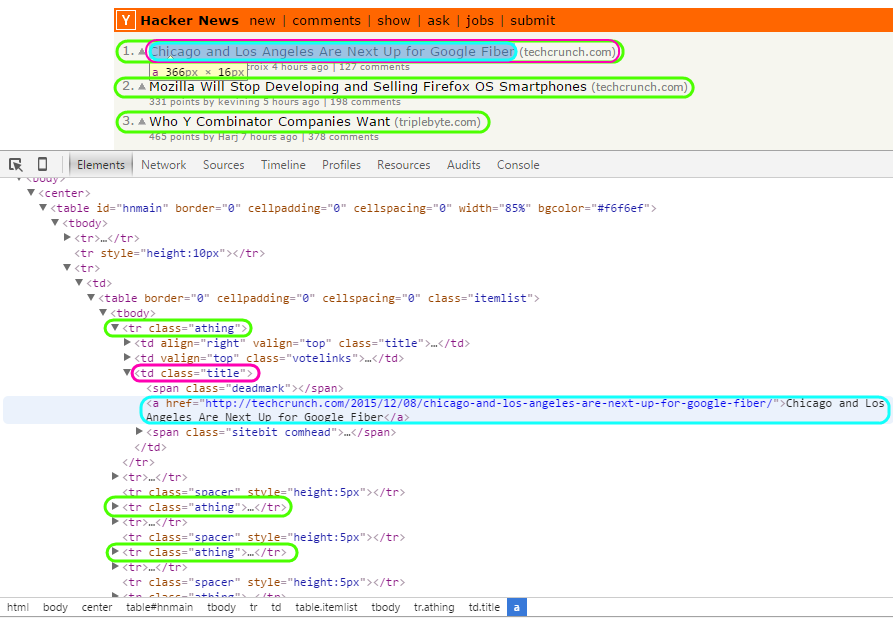
As you can see, there are a bunch of tr HTML elements with a class of athing. So the first step will be to gather up all of the tr.athing elements.
We'll then want to grab the post titles by selecting the td.title child element and then the a element (the anchor tag of the hyperlink).
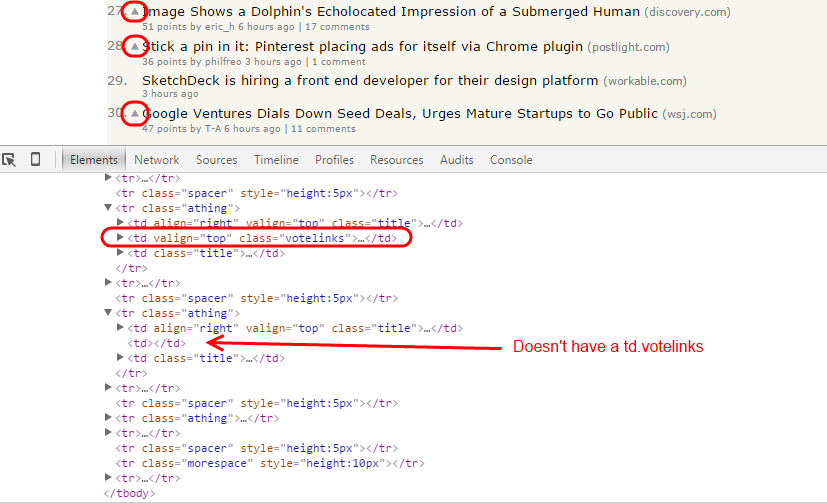
Note that we skip over any hiring posts by making sure we only gather up the tr.athing elements that have a td.votelinks child, as demonstrated in the following picture:
Here's the code
var request = require('request');
var cheerio = require('cheerio');
var fs = require('fs');
request("https://news.ycombinator.com/news", function(error, response, body) {
if(error) {
console.log("Error: " + error);
}
console.log("Status code: " + response.statusCode);
var $ = cheerio.load(body);
$('tr.athing:has(td.votelinks)').each(function( index ) {
var title = $(this).find('td.title > a').text().trim();
var link = $(this).find('td.title > a').attr('href');
fs.appendFileSync('hackernews.txt', title + '\n' + link + '\n');
});
});
Run that and you'll get a hackernews.txt file that looks something like:
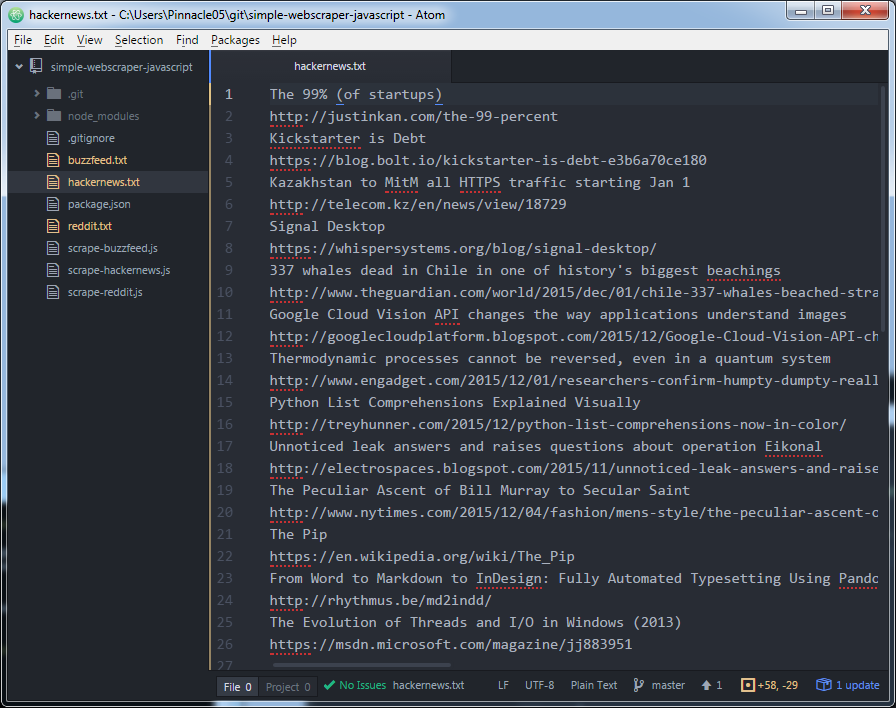
First you have the title of the post on Hacker News and then the URL of that post on the next line. If you wanted both the title and URL on the same line, you can change the code:
fs.appendFileSync('hackernews.txt', title + '\n' + link + '\n');
to something like:
fs.appendFileSync('hackernews.txt', title + ',' + link + '\n');
This allows you to use a comma as a delimiter so you can open up the file in a spreadsheet like Excel or a different program. You may want to use a different delimiter, such as a semicolon, which is an easy change above.
Web Scraping BuzzFeed
var request = require('request');
var cheerio = require('cheerio');
var fs = require('fs');
request("http://www.buzzfeed.com", function(error, response, body) {
if(error) {
console.log("Error: " + error);
}
console.log("Status code: " + response.statusCode);
var $ = cheerio.load(body);
$('div.col1 > ul > li.grid-posts__item').each(function( index ) {
var title = $(this).find('h2 > a').text().trim();
var author = $(this).find('div.small-meta > div:nth-child(1) > a').text().trim();
var responses = $(this).find('div.small-meta > div:nth-child(3) > a').text();
console.log(title);
console.log(author);
console.log(responses);
fs.appendFileSync('buzzfeed.txt', title + '\n' + author + '\n' + responses + '\n');
});
});
Run that and you'll get something like the following in a buzzfeed.txt file:
These People Complaining About "The Wiz" Seem To Have Forgotten That "The Wizard Of Oz" Exists
Andy Neuenschwander
135 responses
It's Time We Realize Britney Spears Is Actually God
Matt Stopera
211 responses
29 Of The Best Awards Show Moments Of 2015
Chelsea Brown
60 responses
Try Stuffing Chicken Parmesan Meatballs With Mozzarella And See What Happens
Andrew Ilnyckyj
11 responses
Apparently In Texas You Get Pickles When You Go To The Movies
Anna Menta
123 responses
What's The Funniest Moment From "Elf"?
Kayla Yandoli
113 responses
This Video Of A Doctor Calming Babies Will Calm You The Eff Down
Alison Caporimo
189 responses
Want more?
I'll eventually update this post to explain how the web scraper works. Specifically I'll talk about how I chose the selectors to pull the correct content from the right HTML element. There are great tools that make this process very easy, such as Chrome DevTools that I use while I'm writing the web scraper for the first time.
I'll also show you how to iterate through the pages on each website to scrape even more content.
Finally, in a future post I'll detail how to insert these records into a database instead of a .txt file. Be sure to check back!
In the mean time, you may be interested in my tutorial on how to create a web crawler in Node.js / JavaScript.