How to make a simple web crawler in Java
A year or two after I created the dead simple web crawler in Python, I was curious how many lines of code and classes would be required to write it in Java. It turns out I was able to do it in about 150 lines of code spread over two classes. That's it!
How does it work?
You give it a URL to a web page and word to search for. The spider will go to that web page and collect all of the words on the page as well as all of the URLs on the page. If the word isn't found on that page, it will go to the next page and repeat. Pretty simple, right? There are a few small edge cases we need to take care of, like handling HTTP errors, or retrieving something from the web that isn't HTML, and avoid accidentally visiting pages we've already visited, but those turn out to be pretty simple to implement. I'll show you how.
I'll be using Eclipse along the way, but any editor will suffice. There are only two classes, so even a text editor and a command line will work.
Let's fire up Eclipse and start a new workspace.
We'll create a new project.
And finally create our first class that we'll call Spider.java.
We're almost ready to write some code. But first, let's think how we'll separate out the logic and decide which classes are going to do what. Let's think of all the things we need to do:
- Retrieve a web page (we'll call it a document) from a website
- Collect all the links on that document
- Collect all the words on that document
- See if the word we're looking for is contained in the list of words
- Visit the next link
Is that everything? What if we start at Page A and find that it contains links to Page B and Page C. That's fine, we'll go to Page B next if we don't find the word we're looking for on Page A. But what if Page B contains a bunch more links to other pages, and one of those pages links back to Page A?
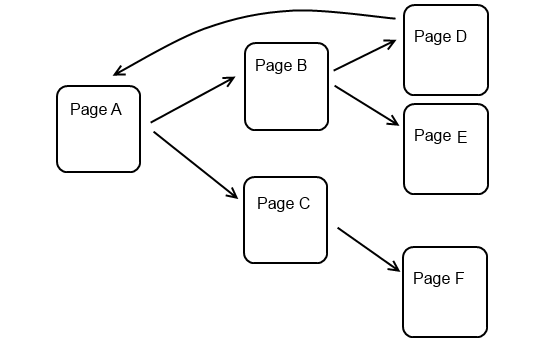
We'll end up back at the beginning again! So let's add a few more things our crawler needs to do:
- Keep track of pages that we've already visited
- Put a limit on the number of pages to search so this doesn't run for eternity.
Let's sketch out the first draft of our Spider.java class:
public class Spider
{
// Fields
private static final int MAX_PAGES_TO_SEARCH = 10;
private Set<String> pagesVisited = new HashSet<String>();
private List<String> pagesToVisit = new LinkedList<String>();
}
Why is pagesVisited a Set? Remember that a set, by definition, contains unique entries. In other words, no duplicates. All the pages we visit will be unique (or at least their URL will be unique). We can enforce this idea by choosing the right data structure, in this case a set.
Why is pagesToVisit a List? This is just storing a bunch of URLs we have to visit next. When the crawler visits a page it collects all the URLs on that page and we just append them to this list. Recall that Lists have special methods that Sets ordinarily do not, such as adding an entry to the end of a list or adding an entry to the beginning of a list. Every time our crawler visits a webpage, we want to collect all the URLs on that page and add them to the end of our big list of pages to visit. Is this necessary? No. But it makes our crawler a little more consistent, in that it'll always crawl sites in a breadth-first approach (as opposed to a depth-first approach).
Remember how we don't want to visit the same page twice? Assuming we have values in these two data structures, can you think of a way to determine the next site to visit?
...
Okay, here's my method for the Spider.java class:
private String nextUrl()
{
String nextUrl;
do
{
nextUrl = this.pagesToVisit.remove(0);
} while(this.pagesVisited.contains(nextUrl));
this.pagesVisited.add(nextUrl);
return nextUrl;
}
A little explanation: We get the first entry from pagesToVisit, make sure that URL isn't in our set of URLs we visited, and then return it. If for some reason we've already visited the URL (meaning it's in our set pagesVisited) we keep looping through the list of pagesToVisit and returning the next URL.
Okay, so we can determine the next URL to visit, but then what? We still have to do all the work of HTTP requests, parsing the document, and collecting words and links. But let's leave that for another class and wrap this one up. This is an idea of separating out functionality. Let's assume that we'll write another class (we'll call it SpiderLeg.java) to do that work and this other class provides three public methods:
public void crawl(String nextURL) // Give it a URL and it makes an HTTP request for a web page
public boolean searchForWord(String word) // Tries to find a word on the page
public List<String> getLinks() // Returns a list of all the URLs on the page
Assuming we have this other class that's going to do the work listed above, can we write one public method for this Spider.java class? What are our inputs? A word to look for and a starting URL. Let's flesh out that method for the Spider.java class:
public void search(String url, String searchWord)
{
while(this.pagesVisited.size() < MAX_PAGES_TO_SEARCH)
{
String currentUrl;
SpiderLeg leg = new SpiderLeg();
if(this.pagesToVisit.isEmpty())
{
currentUrl = url;
this.pagesVisited.add(url);
}
else
{
currentUrl = this.nextUrl();
}
leg.crawl(currentUrl); // Lots of stuff happening here. Look at the crawl method in
// SpiderLeg
boolean success = leg.searchForWord(searchWord);
if(success)
{
System.out.println(String.format("**Success** Word %s found at %s", searchWord, currentUrl));
break;
}
this.pagesToVisit.addAll(leg.getLinks());
}
System.out.println(String.format("**Done** Visited %s web page(s)", this.pagesVisited.size());
}
That should do the trick. We use all of our three fields in the Spider class as well as our private method to get the next URL. We assume the other class, SpiderLeg, is going to do the work of making HTTP requests and handling responses, as well as parsing the document. This separation of concerns is a big deal for many reasons, but the gist of it is that it makes code more readable, maintainable, testable, and flexible.
Let's look at our complete Spider.java class, with some added comments and javadoc:
package com.stephen.crawler;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
public class Spider
{
private static final int MAX_PAGES_TO_SEARCH = 10;
private Set<String> pagesVisited = new HashSet<String>();
private List<String> pagesToVisit = new LinkedList<String>();
/**
* Our main launching point for the Spider's functionality. Internally it creates spider legs
* that make an HTTP request and parse the response (the web page).
*
* @param url
* - The starting point of the spider
* @param searchWord
* - The word or string that you are searching for
*/
public void search(String url, String searchWord)
{
while(this.pagesVisited.size() < MAX_PAGES_TO_SEARCH)
{
String currentUrl;
SpiderLeg leg = new SpiderLeg();
if(this.pagesToVisit.isEmpty())
{
currentUrl = url;
this.pagesVisited.add(url);
}
else
{
currentUrl = this.nextUrl();
}
leg.crawl(currentUrl); // Lots of stuff happening here. Look at the crawl method in
// SpiderLeg
boolean success = leg.searchForWord(searchWord);
if(success)
{
System.out.println(String.format("**Success** Word %s found at %s", searchWord, currentUrl));
break;
}
this.pagesToVisit.addAll(leg.getLinks());
}
System.out.println("\n**Done** Visited " + this.pagesVisited.size() + " web page(s)");
}
/**
* Returns the next URL to visit (in the order that they were found). We also do a check to make
* sure this method doesn't return a URL that has already been visited.
*
* @return
*/
private String nextUrl()
{
String nextUrl;
do
{
nextUrl = this.pagesToVisit.remove(0);
} while(this.pagesVisited.contains(nextUrl));
this.pagesVisited.add(nextUrl);
return nextUrl;
}
}
Okay, one class down, one more to go. Earlier we decided on three public methods that the SpiderLeg class was going to perform. The first was public void crawl(nextURL) that would make an HTTP request for the next URL, retrieve the document, and collect all the text on the document and all of the links or URLs on the document. Unfortunately Java doesn't come with all of the tools to make an HTTP request and parse the page in a super easy way. Fortunately there's a really lightweight and super easy to use package called jsoup that makes this very easy. There's about 700 lines of code to form the HTTP request and the response, and a few thousand lines of code to parse the response. But because this is all neatly bundled up in this package for us, we just have to write a few lines of code ourselves.
For example, here's three lines of code to make an HTTP request, parse the resulting HTML document, and get all of the links:
Connection connection = Jsoup.connect("http://www.example.com")
Document htmlDocument = connection.get();
Elements linksOnPage = htmlDocument.select("a[href]");
That could even be condensed into one line of code if we really wanted to. jsoup is a really awesome project. But how do we start using jsoup?
You import the jsoup jar into your project!
Okay, now that we have access to the jsoup jar, let's get back to our crawler. Let's start with the most basic task of making an HTTP request and collecting the links. Later we'll improve this method to handle unexpected HTTP response codes and non HTML pages.
First let's add two private fields to this SpiderLeg.java class:
private List<String> links = new LinkedList<String>(); // Just a list of URLs
private Document htmlDocument; // This is our web page, or in other words, our document
And now the simple method in the SpiderLeg class that we'll later improve upon
public void crawl(String url)
{
try
{
Connection connection = Jsoup.connect(url).userAgent(USER_AGENT);
Document htmlDocument = connection.get();
this.htmlDocument = htmlDocument;
System.out.println("Received web page at " + url);
Elements linksOnPage = htmlDocument.select("a[href]");
System.out.println("Found (" + linksOnPage.size() + ") links");
for(Element link : linksOnPage)
{
this.links.add(link.absUrl("href"));
}
}
catch(IOException ioe)
{
// We were not successful in our HTTP request
System.out.println("Error in out HTTP request " + ioe);
}
}
Still following? Nothing too fancy going on here. There are two little tricks in that we have to know how to specify all the URLs on a page such as a[href] and that we want the absolute URL to add to our list of URLs.
Great, and if we remember the other thing we wanted this second class (SpiderLeg.java) to do, it was to search for a word. This turns out to be surprisingly easy:
public boolean searchForWord(String searchWord)
{
System.out.println("Searching for the word " + searchWord + "...");
String bodyText = this.htmlDocument.body().text();
return bodyText.toLowerCase().contains(searchWord.toLowerCase());
}
We'll also improve upon this method later.
Okay, so this second class (SpiderLeg.java) was supposed to do three things:
- Crawl the page (make an HTTP request and parse the page)
- Search for a word
- Return all the links on the page
We've just written methods for the first two actions. Remember that we store the links in a private field in the first method? It's these lines:
//... code above
for(Element link : linksOnPage)
{
this.links.add(link.absUrl("href"));
}
//... code below
So to return all the links on the page we just provide a getter to this field
public List<String> getLinks()
{
return this.links;
}
Done!
Okay, let's look at this code in all its glory. You'll notice I added a few more lines to handle some edge cases and do some defensive coding. Here's the complete SpiderLeg.java class:
package com.stephen.crawler;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SpiderLeg
{
// We'll use a fake USER_AGENT so the web server thinks the robot is a normal web browser.
private static final String USER_AGENT =
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.112 Safari/535.1";
private List<String> links = new LinkedList<String>();
private Document htmlDocument;
/**
* This performs all the work. It makes an HTTP request, checks the response, and then gathers
* up all the links on the page. Perform a searchForWord after the successful crawl
*
* @param url
* - The URL to visit
* @return whether or not the crawl was successful
*/
public boolean crawl(String url)
{
try
{
Connection connection = Jsoup.connect(url).userAgent(USER_AGENT);
Document htmlDocument = connection.get();
this.htmlDocument = htmlDocument;
if(connection.response().statusCode() == 200) // 200 is the HTTP OK status code
// indicating that everything is great.
{
System.out.println("\n**Visiting** Received web page at " + url);
}
if(!connection.response().contentType().contains("text/html"))
{
System.out.println("**Failure** Retrieved something other than HTML");
return false;
}
Elements linksOnPage = htmlDocument.select("a[href]");
System.out.println("Found (" + linksOnPage.size() + ") links");
for(Element link : linksOnPage)
{
this.links.add(link.absUrl("href"));
}
return true;
}
catch(IOException ioe)
{
// We were not successful in our HTTP request
return false;
}
}
/**
* Performs a search on the body of on the HTML document that is retrieved. This method should
* only be called after a successful crawl.
*
* @param searchWord
* - The word or string to look for
* @return whether or not the word was found
*/
public boolean searchForWord(String searchWord)
{
// Defensive coding. This method should only be used after a successful crawl.
if(this.htmlDocument == null)
{
System.out.println("ERROR! Call crawl() before performing analysis on the document");
return false;
}
System.out.println("Searching for the word " + searchWord + "...");
String bodyText = this.htmlDocument.body().text();
return bodyText.toLowerCase().contains(searchWord.toLowerCase());
}
public List<String> getLinks()
{
return this.links;
}
}
Why the USER_AGENT? This is because some web servers get confused when robots visit their page. Some web servers return pages that are formatted for mobile devices if your user agent says that you're requesting the web page from a mobile web browser. If you're on a desktop web browser you get the page formatted for a large screen. If you don't have a user agent, or your user agent is not familiar, some websites won't give you the web page at all! This is rather unfortunate, and just to prevent any troubles, we'll set our user agent to that of Mozilla Firefox.
Ready to try out the crawler? Remember that we wrote the Spider.java class and the SpiderLeg.java class. Inside the Spider.java class we instantiate a spiderLeg object which does all the work of crawling the site. But where do we instantiate a spider object? We can write a simple test class (SpiderTest.java) and method to do this.
package com.stephen.crawler;
public class SpiderTest
{
/**
* This is our test. It creates a spider (which creates spider legs) and crawls the web.
*
* @param args
* - not used
*/
public static void main(String[] args)
{
Spider spider = new Spider();
spider.search("http://arstechnica.com/", "computer");
}
}
Further Reading
My original how-to article on making a web crawler in 50 lines of Python 3 was written in 2011. I also wrote a guide on making a web crawler in Node.js / Javascript. Check those out if you're interested in seeing how to do this in another language.
If Java is your thing, a book is a great investment, such as the following.


I know that the Effective Java book is pretty much required reading at a lot of tech companies using Java (such as Amazon and Google). Joshua Bloch is kind of a big deal in the Java world.
Good luck!