How to make a web crawler in JavaScript / Node.js
The two most popular posts on this blog are how to create a web crawler in Python and how to create a web crawler in Java. Since JavaScript is increasingly becoming a very popular language thanks to Node.js, I thought it would be interesting to write a simple web crawler in JavaScript.
Here's my first attempt at a web crawler. I was able to do it in about 70 lines of code. The full code is included at the bottom with plenty of comments breaking it down and explaining each step.
Maybe in future posts I'll have it connect to a database and store keywords/URLs, and then a basic web app that lets you type in those keywords that query the database and return the URL (this is closer to how real search engines work). But let's start with the web crawler first.
How it works
The web crawler (or spider) is pretty straight forward. You give it a starting URL and a word to search for. The web crawler will attempt to find that word on the web page it starts at, but if it doesn't find it on that page it starts visiting other pages. Pretty basic, right? Like the Python and Java implementation, there are a few edge cases we need to handle such as not visiting the same page, or dealing with HTTP errors, but those aren't hard to implement.
Let's get started!
Pre-requisites
You need to have Node.js and npm (Node Package Manager) installed on your computer since we'll be using it to execute the JavaScript. You can verify you have both installed by running node --version and npm --version in a shell or command line. On a Windows machine it looks like this:
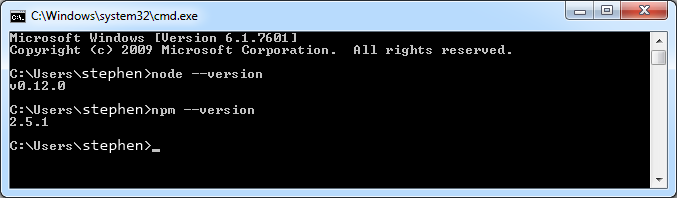
It's okay if your versions are a little newer. I have slightly older versions, but new ones should work just as well. If you don't have these packages installed, you can get both by heading over to the node.js downloads page which should install both Node.js and npm at the same time.
Creating the web crawler in JavaScript
Let's remind ourselves what we're trying to do:
- Get a web page
- Try to find a word on a given web page
- If the word isn't found, collect all the links on that page so we can start visiting them
Let's start coding each of those steps up. I'll be using Atom as my text editor to write the code, but there are other great text editors out there such as Sublime Text or Notepad++. I've used all three at various points in my life and you can't go wrong with any one of them.
Go ahead and create an empty file we'll call crawler.js and add these three lines:
var request = require('request');
var cheerio = require('cheerio');
var URL = require('url-parse');
In Atom it looks like this:
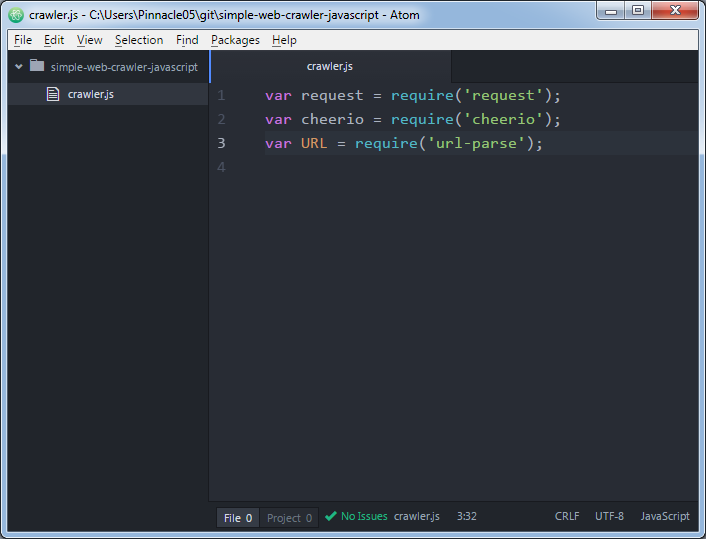
These are the three libraries in this web crawler that we'll use. Request is used to make HTTP requests. Cheerio is used to parse and select HTML elements on the page. And URL is used to parse URLs.
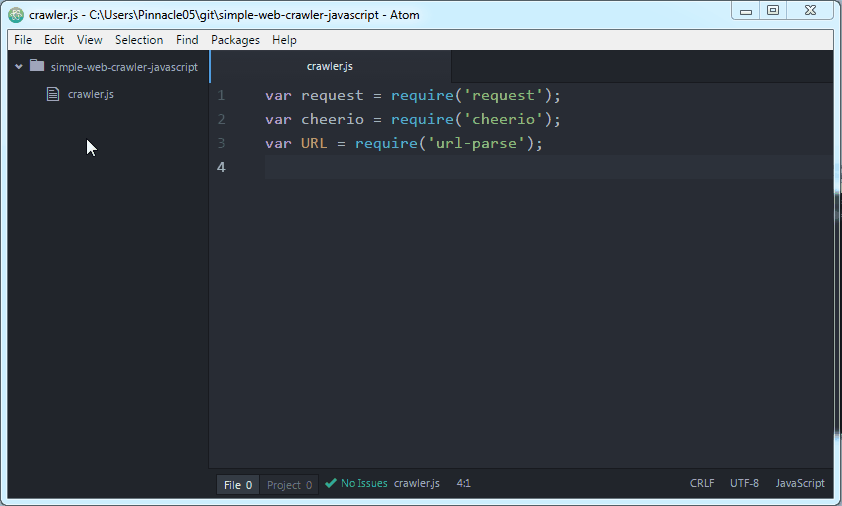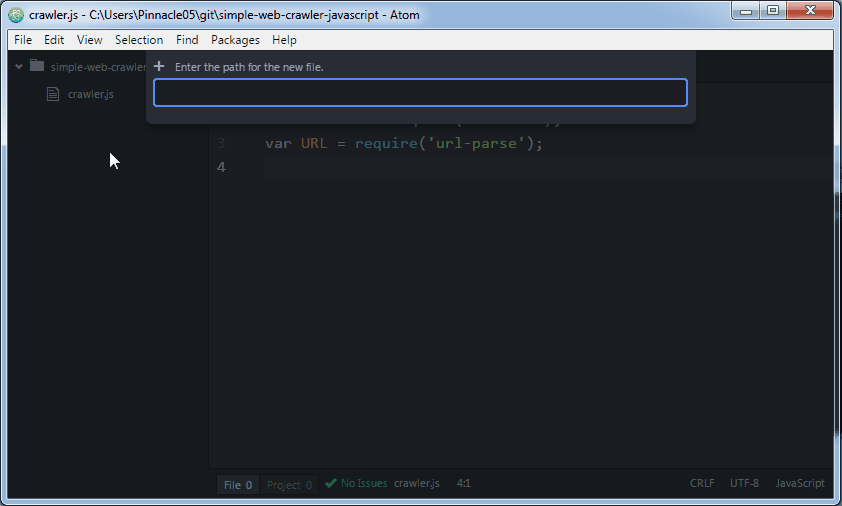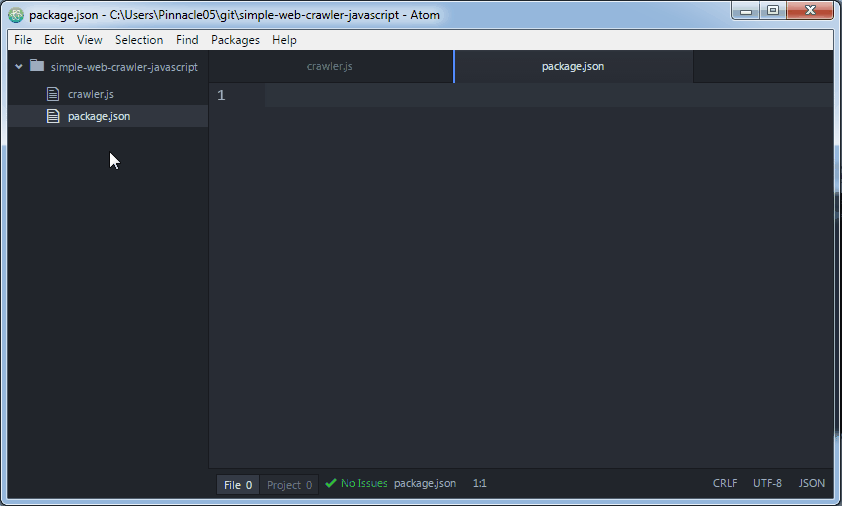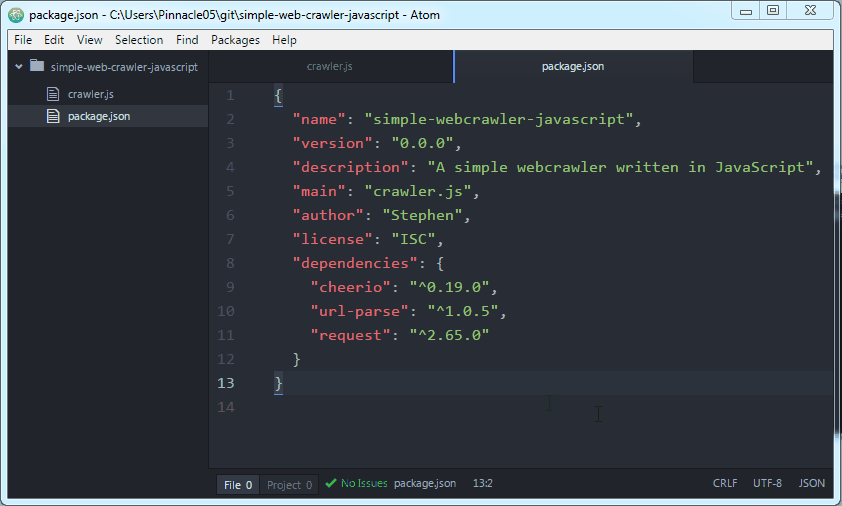
Now we'll use npm (node package manager) to actually install these three libraries. I've created a file called package.json that describes this project and specifies the dependencies.
{
"name": "simple-webcrawler-javascript",
"version": "0.0.0",
"description": "A simple webcrawler written in JavaScript",
"main": "crawler.js",
"author": "Stephen",
"license": "ISC",
"dependencies": {
"cheerio": "^0.19.0",
"url-parse": "^1.0.5",
"request": "^2.65.0"
}
}
If you have this package.json file in your project folder, all you need to do is run npm install from that location and it will fetch and install the libraries.
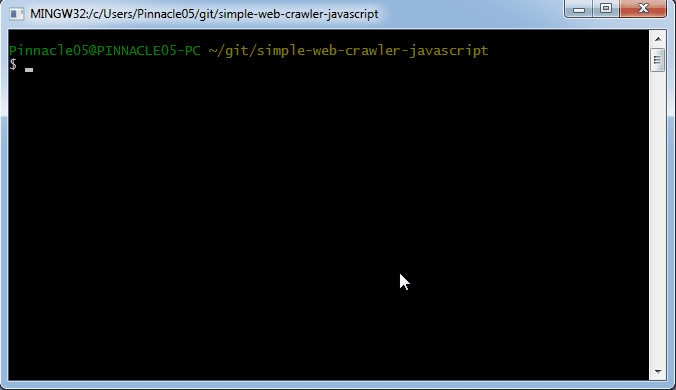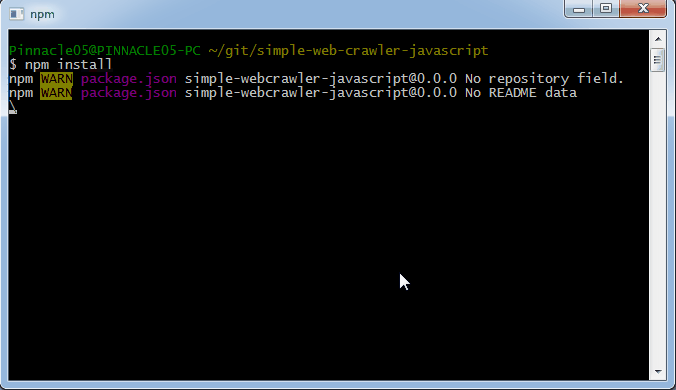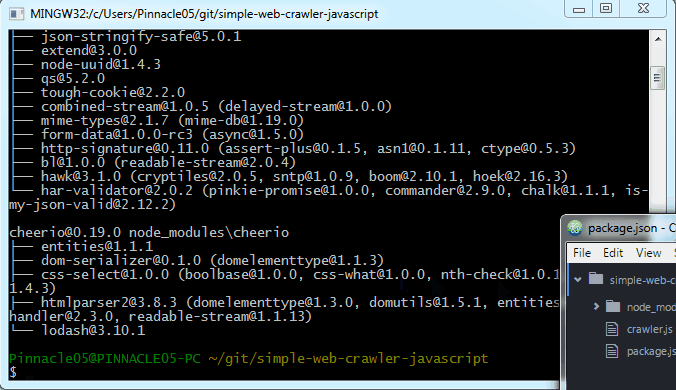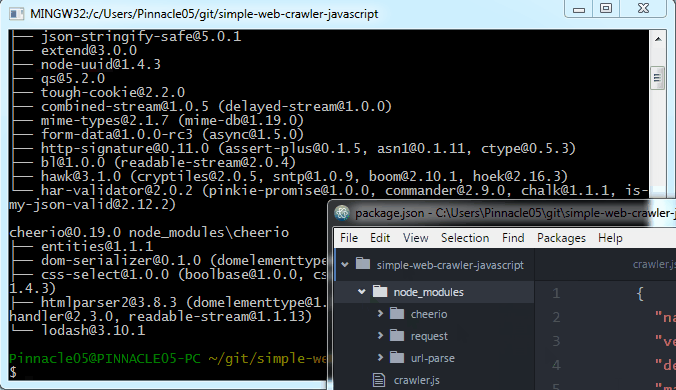
As you can see, it creates a directory called node_modules with the libraries installed there. Now we can use them!
Fetching and parsing a web page in JavaScript
Fetching a page is pretty simple. Here's how we go about it:
var pageToVisit = "http://www.arstechnica.com";
console.log("Visiting page " + pageToVisit);
request(pageToVisit, function(error, response, body) {
if(error) {
console.log("Error: " + error);
}
// Check status code (200 is HTTP OK)
console.log("Status code: " + response.statusCode);
if(response.statusCode === 200) {
// Parse the document body
var $ = cheerio.load(body);
console.log("Page title: " + $('title').text());
}
});
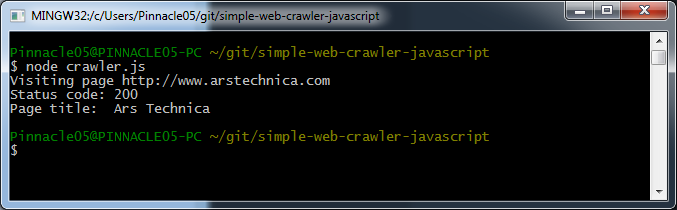
We use the library request to visit the page and then execute a callback after we get the response. The callback is the anonymous function that looks like function(error, response, body) {...}
In that function body (the {...} above) we examine the response status code and print it to the console. A 200 OK indicates that everything went ok.
We use cheerio to parse the page body and assign it to the variable $. You may recognize this convention if you're used to jQuery. cheerio let's us use much of the functionality of jQuery to parse the page. Therefore, we can write $('title').text() to select the HTML element such as <title>Page title</title> and display the text within it.
Run the code by typing node crawler.js
Now let's write some helper functions to do the rest of the work.
Parsing the page and searching for a word
Checking to see if a word is in the body of a web page isn't too hard. Here's what that function looks like:
function searchForWord($, word) {
var bodyText = $('html > body').text();
if(bodyText.toLowerCase().indexOf(word.toLowerCase()) !== -1) {
return true;
}
return false;
}
We use the JavaScript function indexOf to check for occurences of a substring in a given string. Note that indexOf is case sensitive, so we have to convert both the search word and the web page to either uppercase or lowercase.
Collecting links on a web page in JavaScript
There are two types of links we'll come across on webpages. Hyperlinks can come as relative paths or absolute paths.
Relative paths look like:
/information-technology
/gadgets
/security
/tech-policy
Absolute paths look like:
http://www.arstechnica.com/information-technology
http://www.arstechnica.com/gadgets
http://www.arstechnica.com/security
http://www.arstechnica.com/tech-policy
http://www.condenast.com
http://www.condenast.com/privacy-policy
You'll notice that relative paths won't ever lead us away from the domain that we start on. Absolute paths could take us anywhere on the internet. That distinction is important when you're building the web crawler. Do you want your crawler to stay on the existing website (in this case arstechnica.com) and search only pages within that domain, or is it acceptable to adventure outside to other websites such as condenast.com? The code below will gather all of the relative hyperlinks as well as all the absolute hyperlinks for a given page:
function collectInternalLinks($) {
var allRelativeLinks = [];
var allAbsoluteLinks = [];
var relativeLinks = $("a[href^='/']");
relativeLinks.each(function() {
allRelativeLinks.push($(this).attr('href'));
});
var absoluteLinks = $("a[href^='http']");
absoluteLinks.each(function() {
allAbsoluteLinks.push($(this).attr('href'));
});
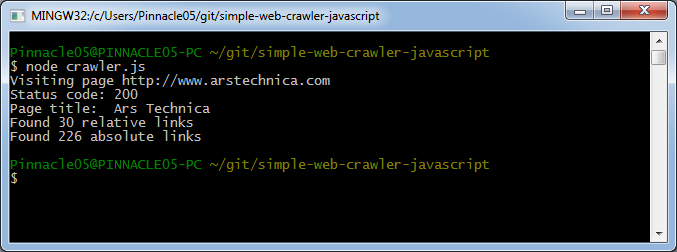
console.log("Found " + allRelativeLinks.length + " relative links");
console.log("Found " + allAbsoluteLinks.length + " absolute links");
}
If we modify the existing crawler.js to execute this function after fetching the page and then run it, we get something like:
Putting it all together
We'll need a place to put all the links that we find on every page. In this simple web crawler we just use an array that we call pagesToVisit.
The last thing we need to do is keep track of which pages we've visited (so we don't visit them more than once). In the Java version of the web crawler we used a Set<String> (specifically a HashSet<String>) that we called pagesVisited and added the URL to that set when we visited it. Before visiting a page, we make sure that the URL is not already in that set. If it is, we skip it.
JavaScript doesn't yet have a set object unless you're using ECMAScript 2015 (ES6) but we can create one fairly easily:
To initialize a set:
var pagesVisited = {};
To add a page to the set:
pagesVisited[url] = true;
To check if the nextPage (the URL) is in the set of pagesVisited:
if (nextPage in pagesVisited) {...}
Remember when we had to decide to follow absolute links or relative links (or both)? In the complete crawler below I decided to only follow relative links. Because of that we have to do some extra work to recreate the links. As an example, given /technology we need to turn it into http://www.arstechnica.com/technology. We use the URL library to achieve this.
The complete code is shown below:
var request = require('request');
var cheerio = require('cheerio');
var URL = require('url-parse');
var START_URL = "http://www.arstechnica.com";
var SEARCH_WORD = "stemming";
var MAX_PAGES_TO_VISIT = 10;
var pagesVisited = {};
var numPagesVisited = 0;
var pagesToVisit = [];
var url = new URL(START_URL);
var baseUrl = url.protocol + "//" + url.hostname;
pagesToVisit.push(START_URL);
crawl();
function crawl() {
if(numPagesVisited >= MAX_PAGES_TO_VISIT) {
console.log("Reached max limit of number of pages to visit.");
return;
}
var nextPage = pagesToVisit.pop();
if (nextPage in pagesVisited) {
// We've already visited this page, so repeat the crawl
crawl();
} else {
// New page we haven't visited
visitPage(nextPage, crawl);
}
}
function visitPage(url, callback) {
// Add page to our set
pagesVisited[url] = true;
numPagesVisited++;
// Make the request
console.log("Visiting page " + url);
request(url, function(error, response, body) {
// Check status code (200 is HTTP OK)
console.log("Status code: " + response.statusCode);
if(response.statusCode !== 200) {
callback();
return;
}
// Parse the document body
var $ = cheerio.load(body);
var isWordFound = searchForWord($, SEARCH_WORD);
if(isWordFound) {
console.log('Word ' + SEARCH_WORD + ' found at page ' + url);
} else {
collectInternalLinks($);
// In this short program, our callback is just calling crawl()
callback();
}
});
}
function searchForWord($, word) {
var bodyText = $('html > body').text().toLowerCase();
return(bodyText.indexOf(word.toLowerCase()) !== -1);
}
function collectInternalLinks($) {
var relativeLinks = $("a[href^='/']");
console.log("Found " + relativeLinks.length + " relative links on page");
relativeLinks.each(function() {
pagesToVisit.push(baseUrl + $(this).attr('href'));
});
}
An example of running the simple crawler is shown below:
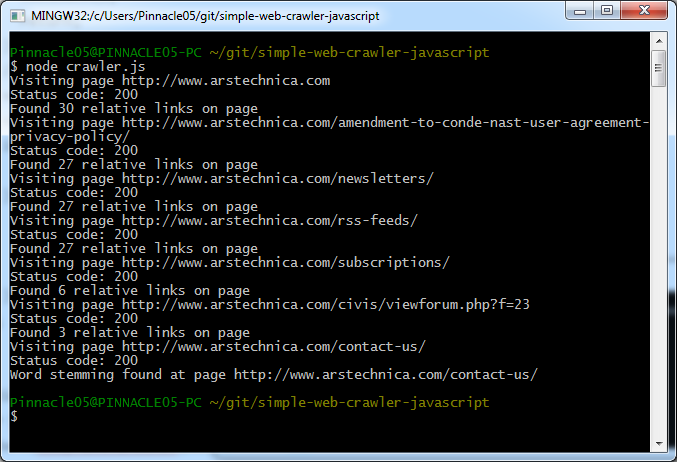
There are some improvements we can make to the code. I'll save those for a future post, but I'll mention them briefly.
- Handle any request errors
- Collect absolute links, but check that they belong to the same domain and then add them to the
pagesToVisitarray - Read in the starting URL and the word to search for as command line arguments
- Use a different User-Agent if there are any problems making requests to websites that filter based on those HTTP headers
Next steps
See my latest tutorial on simple web scraping in Node.js and JavaScript here that explains how to scrape popular websites like reddit, Hacker News, and BuzzFeed.
If you want to make a web cralwer in other programming languages, you may be interested in how to create a web crawler in Python and how to create a web crawler in Java.
Good luck!